PartI:TabularSolutionMethods第一趴解决简单的RL问题,state,action都很小,val...

Part I: Tabular Solution Methods
第一趴解决简单的RL问题,state,action都很小,value funtion可以用array或者table表示,一般能找到最优解,即最优value function和最优policy。第一章讨论一个特殊的RL问题,只有一个state,称为bandit problem。第二章讲finite Markov decision process,他的主要概念包括Bellman equation和value function。之后三章讨论三种finite Markov decision problem的方法:dynamic programming,Monte Carlo methods,temporal-difference learning。Dynamic programming数学推导完整,但要求完整精确的环境信息;Monte Carlo不要求环境且概念上简单,但不适用于incremental calculation;temporal-difference methods不需要环境model且incremental,但很分析起来很复杂。这些方法的效率和收敛速度都有所区别。最后两章将三种方法结合。一章用eligibility trace将Monte Carlo和temporal-difference结合,一章将temporal-difference和model learning,planning methods(such as dynamic programming)结合。Chapter 2 Multi-armed Bandits
RL并不明确结果(instructive feedback),而是给出evaluation(evaluative feedback),这就需要我们去explore。nonassociative setting是evaluation的部分已经确定,其中简单的k-armed badit problem可以让我们了解instructive feedback和evaluative feedback之间的关系。2.1 A k-armed Bandit Problem
k-armed bandit problem包括k个action,每个有相对应的mean reward,称为value of the action。Time t选择的action为2.2 Action-value Methods
一个很自然想到的预测2.3 The 10-armed Testbed
k=10,2000次test,value of action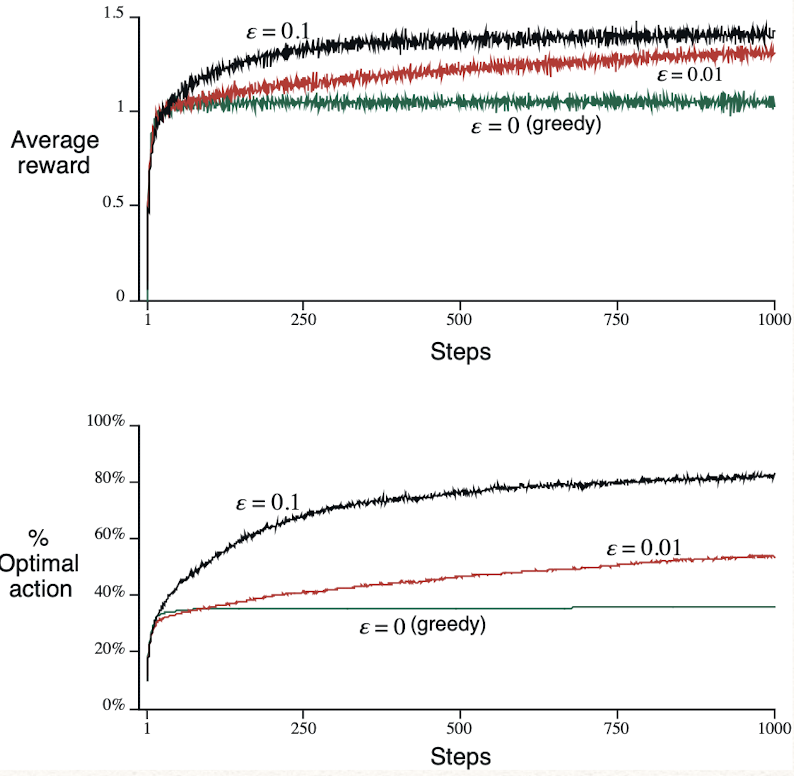
2.4 Incremental Implementation
现在考虑如何用constant memory和constant per-time-step computation来计算sample average。考虑single action。2.5 Tracking a Nonstationary Problem
之前研究的都是stationary bandit problem,reward probabilities不变。RL中更常见的是nonstationary,给最近的reward更多权重就很合理。其中一个常见的方法是将step-size parameter设为constant:2.6 Optimistic Initial Values
之前讨论的都依赖于2.7 Upper-Confidence-Bound Action Selection
对于greedy和epsilon-greedy,更好的方法是选择有potential的action: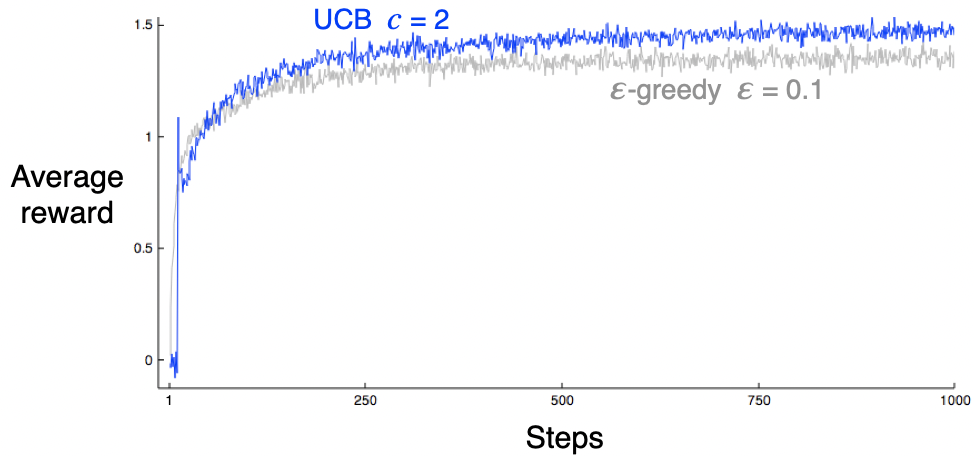 对于nonstationary problems,需要有比weighted average更复杂的方法。
对于nonstationary problems,需要有比weighted average更复杂的方法。2.8 Gradient Bandit Algorithms
出了以上估计value和用value选择action的方法,本节学习actions的numerical preference,表示为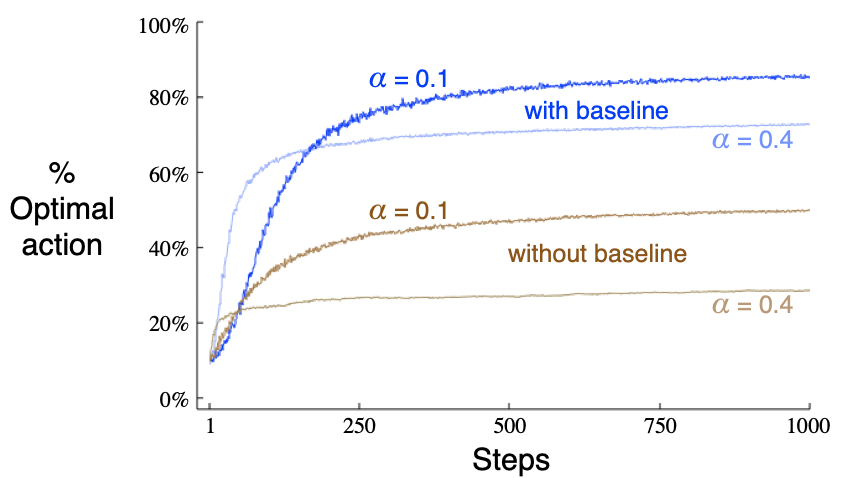 P29: bandit stochastic gradient ascent 可以由 gradient ascent 推导。gradient ascent:
P29: bandit stochastic gradient ascent 可以由 gradient ascent 推导。gradient ascent: 2.9 Associative Search (Contextual Bandits)
以上都是nonassociative tasks(不同action对于所有state都一样),而常见的RL问题是在不同的state选择最优action。不同action在不同state的true value变化很大,不能使用对应nonstationary problem的方法。associative search task包括trial and error,search for the best actions和association,也称为contextual bandits。此类问题像full RL problem,包括学习一个policy,也想bandit problem,使用immediate reward。2.10 Summary
本章列了一些平衡exploration and exploitation的简单方法:epsilon-greedy,UCB,gradient bandit algorithm,initializing estimates optimistically。很难评判哪一种方法最好,因为他们都有parameter。下图展示了在10-armed bandit test中parameter和algorithm的关系,这种图称为parameter study。都是在某一个中间值效果最好。总的来说,UCB效果最好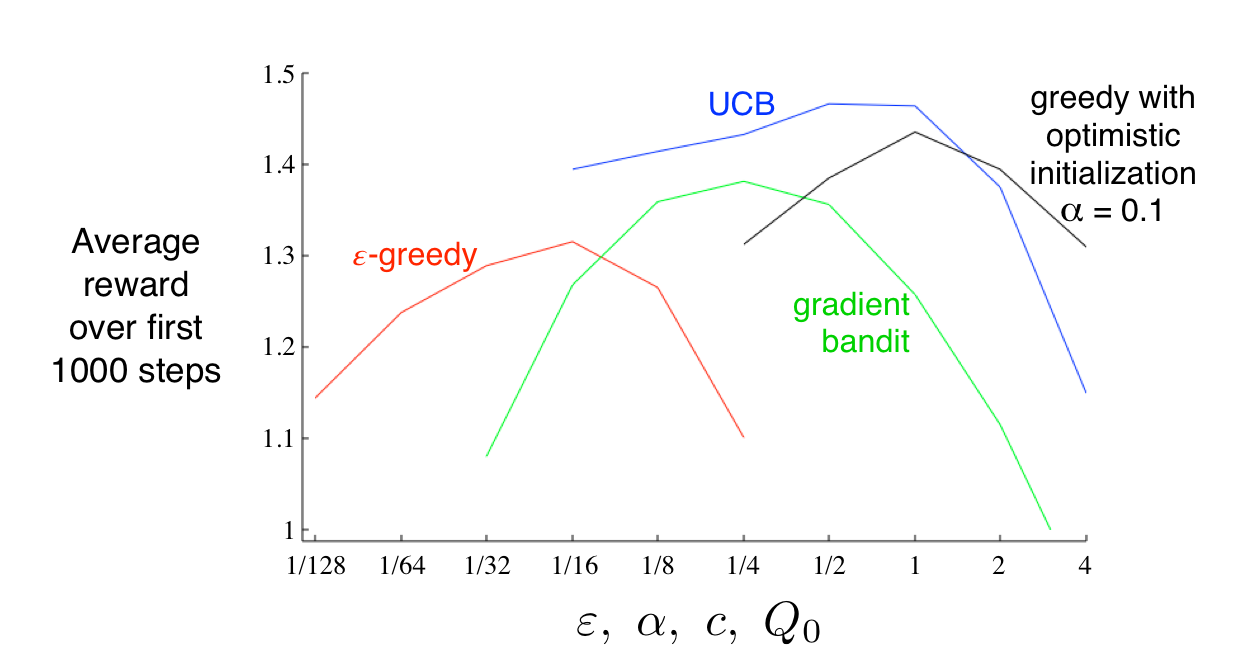 虽然本章中的方法都很简单,但其实sota。复杂的方法在实际中难以应用。Gittins indices是平衡exploration and exploitation的一种方法,找到更general bandit problem 的 optimal solution,但要求分布已知,在full RL problem中唔得。Bayesian methods设置initial distribution,然后一步步update,一般来说update的计算很复杂,但对于一些分布(conjugate priors)很简单。这种方法称为posterior sampling 或者 Thompson sampling,一般和不知distribution的方法表现差不多。在Bayesian中,甚至可以计算optimal balance between exploration and exploitation,将distribution也作为问题的information state。给定horizon,我们可以计算所有的可能,但是所有可能的数量也会指数增长。不能精确计算,但可以approximate。
虽然本章中的方法都很简单,但其实sota。复杂的方法在实际中难以应用。Gittins indices是平衡exploration and exploitation的一种方法,找到更general bandit problem 的 optimal solution,但要求分布已知,在full RL problem中唔得。Bayesian methods设置initial distribution,然后一步步update,一般来说update的计算很复杂,但对于一些分布(conjugate priors)很简单。这种方法称为posterior sampling 或者 Thompson sampling,一般和不知distribution的方法表现差不多。在Bayesian中,甚至可以计算optimal balance between exploration and exploitation,将distribution也作为问题的information state。给定horizon,我们可以计算所有的可能,但是所有可能的数量也会指数增长。不能精确计算,但可以approximate。
本文标题: Intro to RL Chapter 2: Multi-armed Bandits
本文地址: http://www.lzmy123.com/duhougan/142667.html















如果认为本文对您有所帮助请赞助本站