搜索和推荐是解决信息过载的两种主要手段。搜索主要解决用户的明确信息需求,而推荐主要解决用户的非明确信息需求。美团推荐的基本框架如...

搜索和推荐是解决信息过载的两种主要手段。搜索主要解决用户的明确信息需求,而推荐主要解决用户的非明确信息需求。
美团推荐的基本框架如下所示:
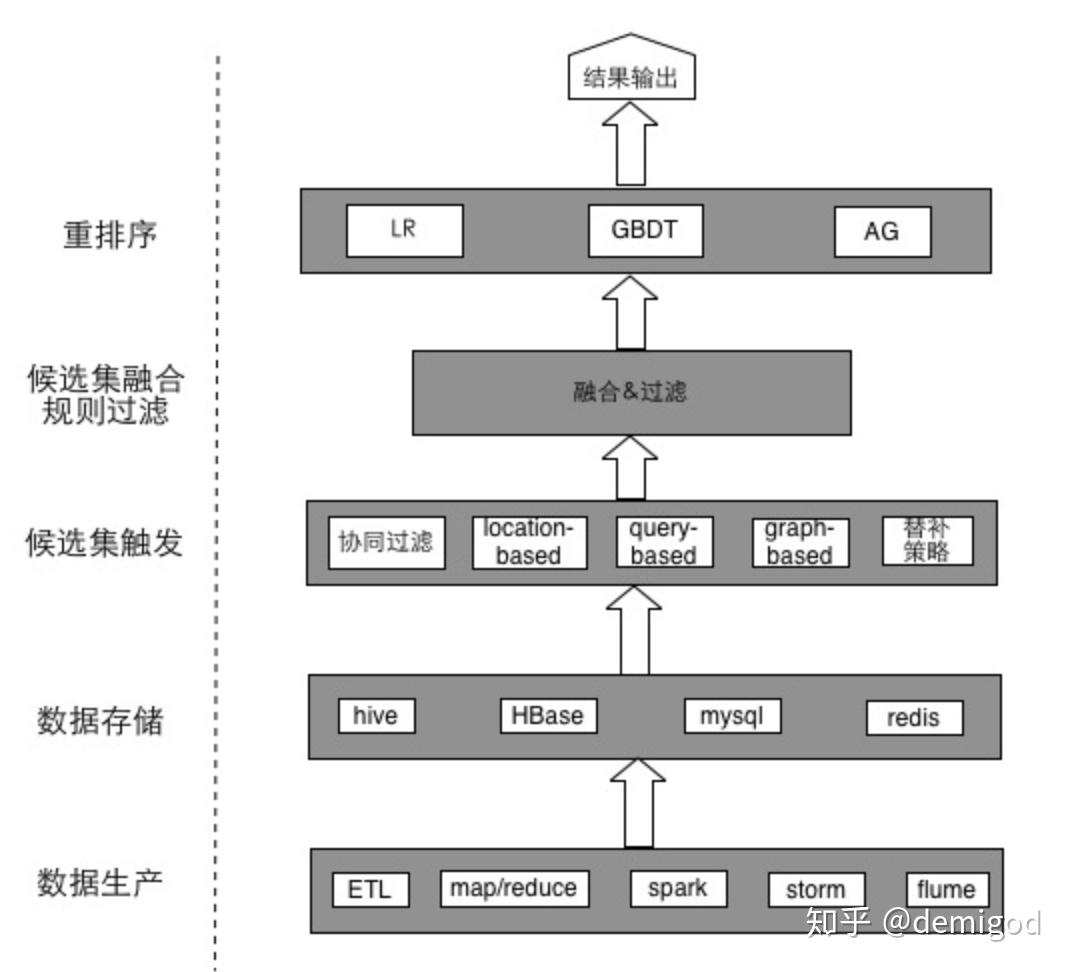
主要分为四个部分:数据层、触发层、融合过滤层和排序层。为了支持效果迭代,触发层和排序层做了解耦,彼此的结果是正交的,因此可以分别进行对比实验。同时,在同一层内部,他们根据用户将流量划分为多分,支持多个策略同时在线对比。
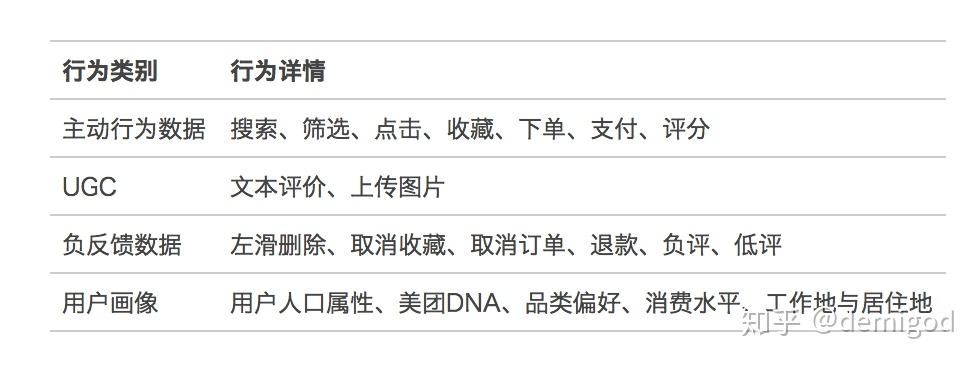
美团使用的数据主要是以下几类:
候选集触发中用到的相关算法:
协同过滤
清除作弊、刷单、代购等噪声数据。这些数据的存在会严重影响算法的效果,需要在第一步中将它们清洗掉。合理选取训练数据。选取的训练数据的时间窗口需要多次实验来确定,不宜过长或者过短。同时可以考虑引入时间衰减,因为近期的用户行为更能反映用户接下来的行为动作。user-based和item-based相结合。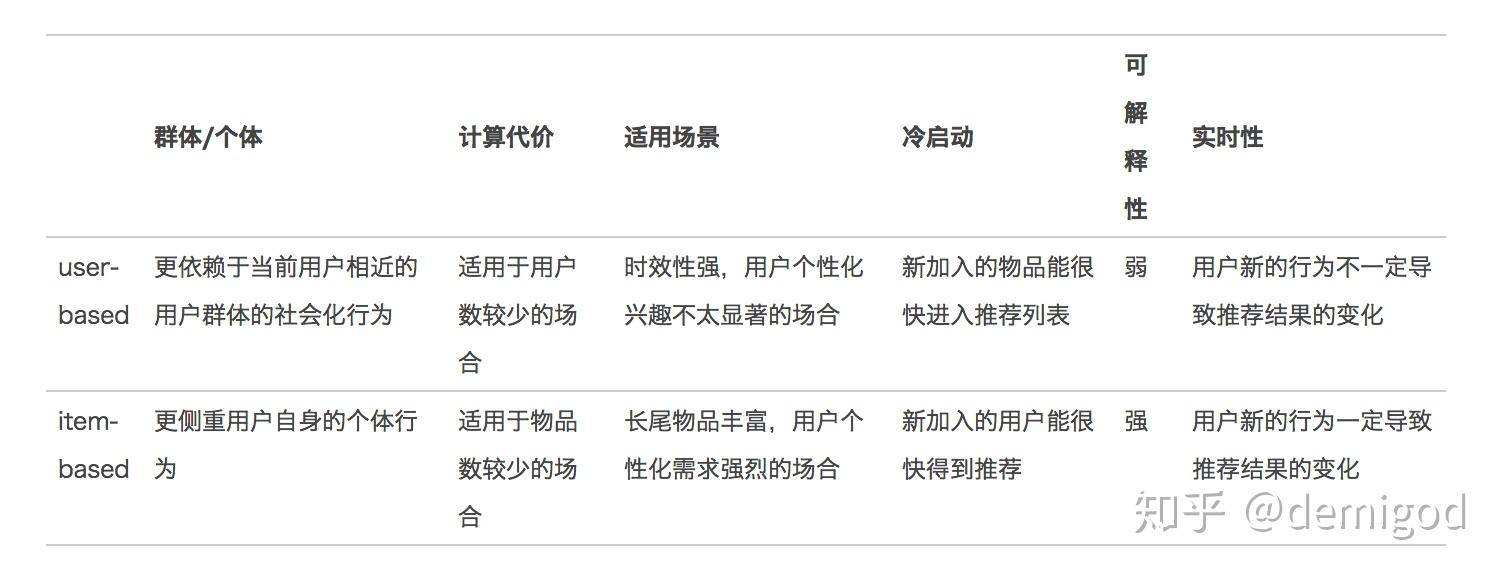 尝试不同相似度计算方法,这里采用了Log-Likelihood Ratio方法。LLR算法的详细介绍在这里http://tdunning.blogspot.com/2008/03/surprise-and-coincidence.html
尝试不同相似度计算方法,这里采用了Log-Likelihood Ratio方法。LLR算法的详细介绍在这里http://tdunning.blogspot.com/2008/03/surprise-and-coincidence.htmllocation-based
移动设备的特点在于用户会经常移动,不同地理位置表示不同用户场景。具体在候选集触发的时候,需要考虑到用户当前的地理位置信息进行推荐。
根据用户的历史消费、历史浏览等,挖掘出某一粒度的区域(比如商圈)内的区域消费热单和区域购买热单。在候选集触发或者排序层,根据用户的地理位置和相应的热单对推荐结果进行加权。也可以根据用户的地理位置,通过协同过滤的方法计算相似度。query-based
搜索是一种强用户意图,反映了用户的明确意愿。在某些情况下,用户的搜索没有形成转换,尽管如此,这些场景依然代表了一定的用户意愿,具有信息量。
对用户过去一段时间的搜索无转换行为进行挖掘,计算每一个用户对不同query的权重。计算每个query下不同deal的权重。当用户再次请求时,根据用户对不同query的权重以及每个query下不同deal的权重进行加权,取出权重最大的TopN进行排序。graph-based
对于协同过滤而言,user之间或者deal之间的图距离是两跳,对于更远距离的关系则不能考虑在内。这里他们使用了simrank[http://ilpubs.stanford.edu:8090/508/1/2001-41.pdf]方法来计算相似度。计算得到相似度矩阵后,可以类似协同过滤进行线上推荐。
实时用户行为
这一部分其实就是利用用户的实时上下文行为给出相关推荐。
替补策略
冷启动或者长尾用户使用,包括热销单、好评单、城市单等。
排序算法
美团的排序算法同时使用了非线性模型和线性模型
非线性模型使用了AG算法。线性模型引入了online learning,因此使用了FTRL方法。数据采样
由于正负样本不均衡,因此必须对负样本进行采样,采样方法使用了skip-above。用户点击转化的数据作为正例,用户主动删除的结果作为高质量负例。
特征
deal特征:价格、折扣、销量、评分、类别、点击率等。user维度的特征:包括用户等级、用户的人口属性、用户的客户端类型等。user、deal的交叉特征:包括用户对deal的点击、收藏、购买等。距离特征:包括用户的实时地理位置、常去地理位置、工作地、居住地等与poi的距离。总结
毕竟是2021年的文章,提出的方法按照现在的眼光看不是最新的,但是从项目的实践效果上看还是很不错的。文章中提出了很多调研时所面临的实际问题,在其他领域也会遇到,因此他们的解决方案值得在自己的项目中参考使用。















如果认为本文对您有所帮助请赞助本站